 Black Hat 2020
Black Hat 2020
Nadie gastaría millones de dólares para proteger una empresa cuyo daño real en caso de incidente no llegaría a exceder unos cuantos miles. Qué tontería, ¿no? Igual de tonto sería racanear unos 100 euros en seguridad si los daños potenciales de una filtración de datos pudieran sumar cientos de miles de euros. Pero ¿qué información debería utilizar para calcular el daño aproximado que sufriría una empresa por un ciberincidente y cómo se mide la probabilidad real de que se produzca un incidente de este tipo? En la conferencia Black Hat 2020, dos investigadores, el profesor Wade Baker de Virginia Tech y David Seversky, analista senior de Cyentia Institute, presentaron su punto de vista sobre la evaluación de riesgos. Creemos que merece la pena debatir sus argumentos.
Cualquier curso de ciberseguridad que se precie enseña que la evaluación de riesgos se basa en dos factores principales: la probabilidad de un incidente y sus pérdidas potenciales. Pero ¿de dónde provienen esos datos y, lo que es más importante, cómo deben interpretarse? Después de todo, evaluar las posibles pérdidas de forma incorrecta conduce a conclusiones incorrectas, lo que provoca que las estrategias de protección no sean óptimas.
¿Es indicativa la media aritmética?
Muchas empresas realizan estudios de las pérdidas financieras causadas por incidentes de filtración de datos. Sus “hallazgos clave” suelen basarse en los promedios de pérdidas de empresas de tamaño similar. El resultado es matemáticamente válido y la cifra queda muy bien en los titulares, pero ¿podemos realmente confiar en él para calcular los riesgos?
Si representas esos mismos datos en un gráfico, con pérdidas a lo largo del eje horizontal y el número de incidentes que causaron las pérdidas a lo largo del eje vertical, resulta obvio que la media aritmética no es el indicador correcto.
En el 90 % de los incidentes, las pérdidas medias son inferiores a la media aritmética.
Si hablamos de las pérdidas que sufriría la empresa promedio, entonces tiene más sentido mirar otros indicadores, en concreto, la mediana (el número que divide la muestra en dos partes iguales de modo que la mitad de las cifras reportadas sean más altas y la otra mitad, inferiores) y la media geométrica (una media proporcional). La mayoría de las empresas sufren esas pérdidas. La media aritmética puede producir una cifra muy confusa debido a un pequeño número de incidentes periféricos con pérdidas anormalmente grandes.

Distribución de pérdidas de incidentes de violación de datos. Fuente
Coste promedio del registro de datos filtrados
Otro ejemplo de un “promedio” cuestionable proviene del método de calcular las pérdidas de los incidentes de violación de datos al multiplicar el número de registros de datos afectados por la cantidad promedio de los daños de la pérdida de un registro de datos. La práctica ha demostrado que este método subestima las pérdidas de los pequeños incidentes y sobreestima seriamente las pérdidas de los grandes.
Por ejemplo, hace un tiempo, se extendió una noticia por muchos sitios de análisis que afirmaba que los servicios en la nube mal configurados habían costado a las empresas casi 5 billones de dólares. Si investigas la procedencia de esta cantidad astronómica, queda claro que la cifra de 5 billones de dólares provino simplemente de multiplicar el número de registros “filtrados” por el promedio de daños de la pérdida de un registro (150 dólares). Esta última cifra proviene del estudio del coste de una violación de datos Ponemon Institute en el 2019.
Sin embargo, esta historia debería resaltar una serie de advertencias. En primer lugar, el estudio no tuvo en cuenta todos los incidentes. En segundo lugar, incluso cuando consideramos solo la muestra utilizada, la media aritmética no ofrece una idea clara de las pérdidas; solo considera casos de registros cuya pérdida causaría daños de menos de 10.000 dólares y más de 1 centavo. Además, la metodología del estudio confirma que el promedio no es válido para incidentes en los que se hayan visto afectados más de 100.000 registros. Por lo tanto, multiplicar el número total de registros que se filtraron como resultado de servicios en la nube mal configurados por 150 es del todo incorrecto.
Para que este método produzca una verdadera evaluación del riesgo, debe incluir otro indicador de la probabilidad de pérdidas según la escala del incidente. Que sería aproximadamente de la siguiente forma:
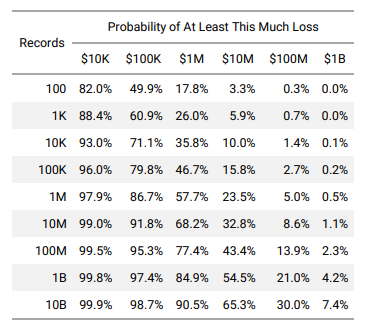
Dependencia de la probabilidad de pérdidas en el número de registros afectados por el incidente. Fuente
El efecto dominó
Otro factor que a menudo se pasa por alto al calcular el coste de un incidente es que las fugas de datos actuales afectan a los intereses de más de una sola empresa. En muchos incidentes, los daños totales que sufren empresas de terceros (socios, contratistas y proveedores) superan los daños en la empresa de la que se filtraron los datos.
El número de incidentes de este tipo aumenta cada año; la tendencia general de “digitalización” solo aumenta el nivel de interdependencia entre los procesos comerciales en diferentes empresas. Según los resultados de este estudio, realizado conjuntamente por RiskRecon y Cyentia Institute, 813 incidentes supusieron pérdidas para 5.437 organizaciones. Es decir, por cada empresa que ha sufrido una violación de datos, en promedio, más de cuatro empresas se ven afectadas por el incidente.
Consejos prácticos
Por tanto, como conclusión, podemos afirmar que los expertos sensatos que evalúan los riesgos cibernéticos deben prestar atención a los siguientes consejos:
- No confíes en los titulares de noticias llamativos. Aunque muchos sitios compartan cierta información, no necesariamente esta tiene por qué ser correcta. Comprueba siempre la fuente que respalda la noticia y analiza por ti mismo la metodología de los investigadores.
- Utiliza solo resultados de investigación que comprendas a fondo de acuerdo con tu evaluación de riesgos.
- Ten en cuenta que un incidente en tu empresa puede generar la pérdida de datos en otras empresas. Si se produce una fuga por tu culpa, es probable que las otras partes interpongan un recurso legal en tu contra, aumentando tus daños por el incidente.
- Asimismo, no olvides que los socios y contratistas pueden filtrar tus datos en incidentes en los que no puedes influir de ninguna forma.

 Consejos
Consejos