Inteligencia artificial y aprendizaje automático en la ciberseguridad
Samuel Arthur, un pionero en la inteligencia artificial, describe la IA como un conjunto de métodos y tecnologías que "ofrecen a los equipos la capacidad de aprender sin que se programen explícitamente". En un caso particular de aprendizaje supervisado antimalware, la tarea se puede formular de la siguiente manera: dado un conjunto de características de objeto \( X \) y las etiquetas \( Y \) de objeto correspondiente como entrada, crea un modelo que produzca las etiquetas \( Y' \) correctas para los objetos de prueba \( X' \) desconocidos hasta entonces. \( X \) podrían ser algunas funciones que representen el contenido o el comportamiento de un archivo (estadísticas de archivos, lista de funciones de API usadas, etc.) y las etiquetas \( Y \) podrían ser simplemente "malware" o "elementos benignos" (en casos más complejos, podríamos estar interesados en una clasificación detallada como virus, descargador de troyanos, adware, etc.). En el caso de un aprendizaje sin supervisión, nos interesa más revelar estructuras ocultas en los datos; encontrar, por ejemplo, grupos de recursos similares o funciones altamente correlacionadas.
La protección multicapa de última generación de Kaspersky usa enfoques de IA como el aprendizaje automático de forma extensiva en todas las etapas del proceso de detección, desde los métodos de agrupación en clúster escalables que se usan para el procesamiento preliminar de flujos de archivos entrantes hasta modelos de red neurales profundos, resistentes y compactos para la detección de comportamientos que funcionan directamente en las máquinas de los usuarios. Estas tecnologías están diseñadas para abordar varios requisitos importantes para las aplicaciones de ciberseguridad en el mundo real, que incluye una tasa de falsos positivos bajísima, la capacidad de interpretación de un modelo y la resistencia ante un posible adversario.
Consideremos algunas de las tecnologías de aprendizaje automático más importantes que se utilizan en los productos para endpoints de Kaspersky:
Conjunto de árbol de decisiones
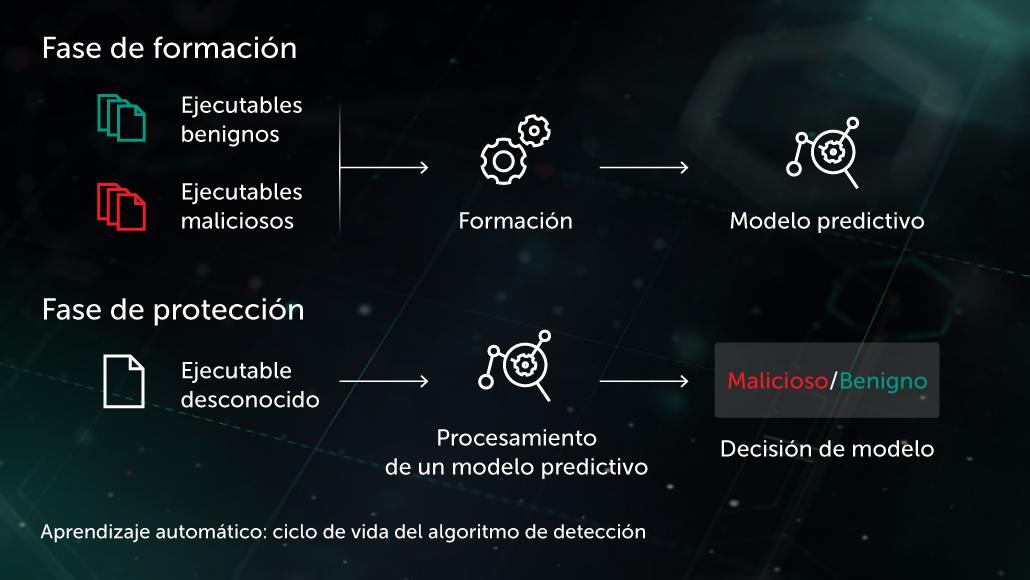
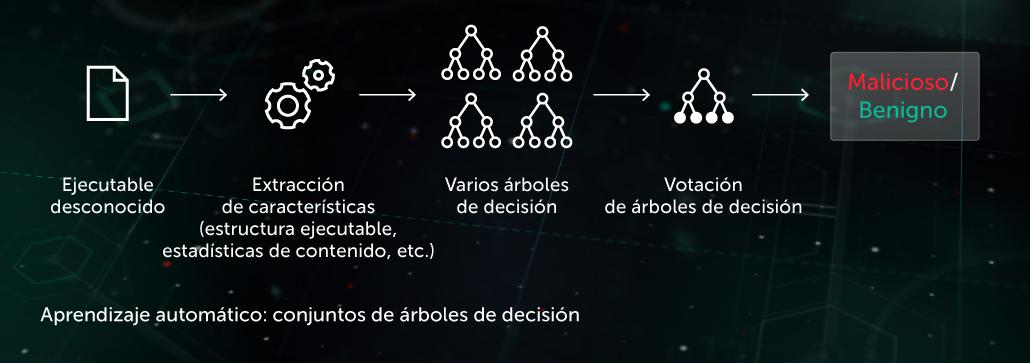
En este enfoque, el modelo predictivo adopta la forma de un conjunto de árboles de decisión (por ejemplo, bosque aleatorio o árboles reforzados con gradientes). Cada nodo de un árbol sin hojas contiene una pregunta acerca de las características del archivo que se va a examinar, mientras que los nodos con hojas contienen la decisión final del archivo sobre el objeto. Durante la fase de prueba, el modelo recorre el árbol respondiendo a las preguntas de los nodos con las características correspondientes del objeto en cuestión. En la etapa final, las decisiones de varios árboles se promedian de una manera específica para algoritmos con el fin de proporcionar una decisión final sobre el objeto.
El modelo beneficia a la etapa de protección proactiva de ejecución previa en el sitio del endpoint. Una de nuestras aplicaciones de esta tecnología es Cloud ML para Android utilizada para la detección de amenazas móviles.
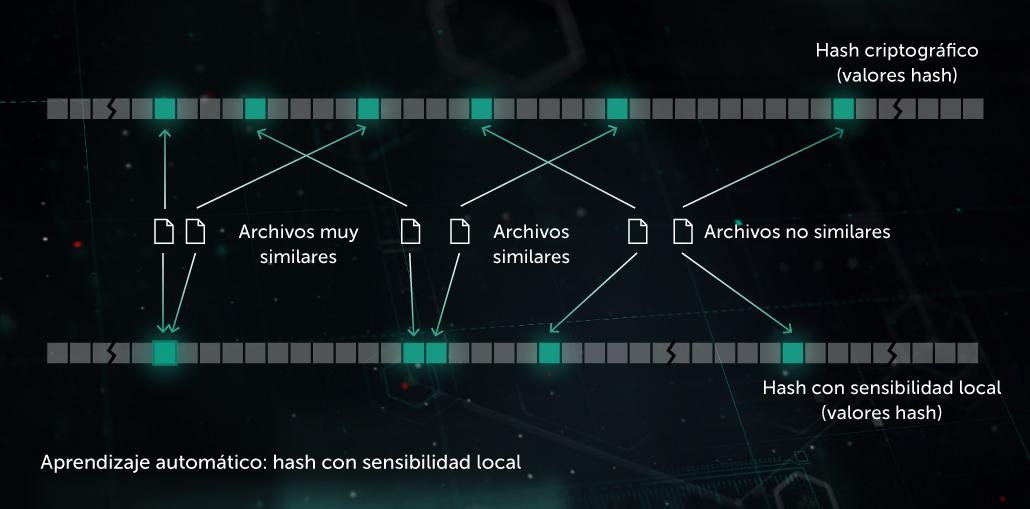
Similitud de hash (hash con sensibilidad local)
En el pasado, los hashes usados para crear "huellas" de malware eran sensibles a cada pequeño cambio en un archivo. Los creadores de malware aprovecharon este inconveniente mediante técnicas de ofuscación, como el polimorfismo en el servidor: cambios menores en el malware que pasaban inadvertidos. El hash de similitud (o hash con sensibilidad local) es un método de IA para detectar archivos maliciosos similares. Para ello, el sistema extrae las características del archivo y utiliza aprendizaje de proyección ortogonal para elegir las características más importantes. Luego, se aplica la compresión basada en aprendizaje automático para que los vectores de valor de características similares se transformen en patrones similares o idénticos. Este método proporciona una buena generalización y reduce notablemente el tamaño de la base de los registros de detección, ya que un registro ahora puede detectar a toda la familia de malware polimórfico.
El modelo beneficia a la etapa de protección proactiva de ejecución previa en el sitio del endpoint. Se aplica en nuestro Sistema de detección de similitud de hash.
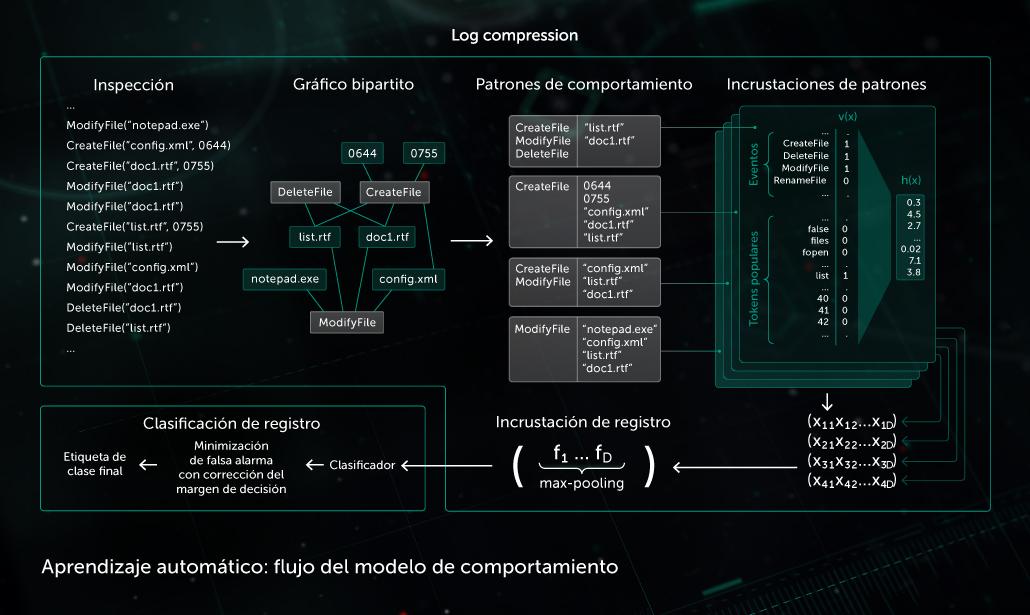
Modelo de conducta
Un componente de supervisión proporciona un registro de comportamiento: la secuencia de eventos del sistema ocurridos durante la ejecución del proceso junto con los argumentos correspondientes. Con el fin de detectar actividad maliciosa en los datos de registro observados, nuestro modelo comprime la secuencia de eventos obtenida en un conjunto de vectores binarios y entrena la red neuronal profunda para distinguir los registros maliciosos y limpios.
Los módulos de detección estática y dinámica usan la clasificación de objetos realizada por el modelo de comportamiento en los productos Kaspersky del lado del endpoint.
La IA también desempeña un papel importante cuando se trata de crear una infraestructura adecuada de procesamiento de malware en el laboratorio. Kaspersky lo utiliza para los siguientes fines de infraestructura:
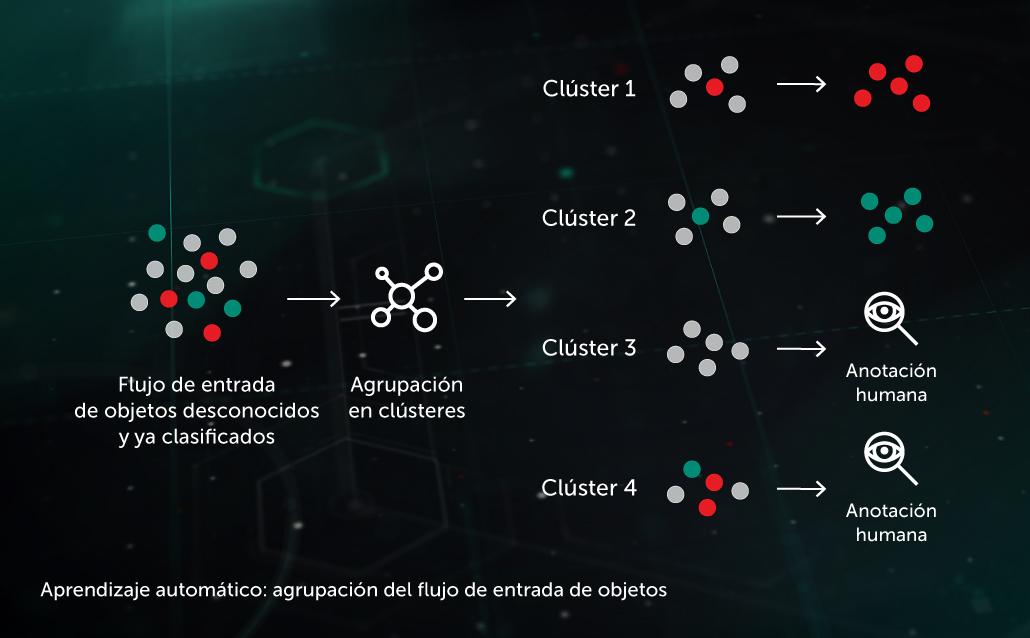
Clústeres de flujo entrante
Los algoritmos de clústeres basados en aprendizaje automático nos permiten separar eficazmente los grandes volúmenes de archivos desconocidos que entran en nuestra infraestructura en un número razonable de clústeres, algunos de los cuales se pueden procesar automáticamente en función de la presencia de un objeto ya anotado en su interior.
Modelos de clasificación a gran escala
Algunos de los modelos de clasificación más potentes (como un gran bosque aleatorio de decisiones) requieren una cantidad considerable de recursos (tiempo del procesador, memoria) junto con costosos extractores de funciones (por ejemplo, podría necesitarse el procesamiento a través de sandbox para obtener registros detallados de comportamiento). Por lo tanto, es más eficaz mantener y ejecutar los modelos en un laboratorio y luego convertir el conocimiento obtenido por dichos modelos mediante la capacitación de un modelo de clasificación ligero en las decisiones de salida del modelo más grande.
Seguridad en el uso de los aspectos del aprendizaje automático de la IA
LLos algoritmos de aprendizaje automático, una vez liberados de los confines del laboratorio al mundo real, podrían ser vulnerables a muchas formas de ataques diseñados para forzar a los sistemas de IA a cometer errores deliberados. Un atacante puede envenenar un conjunto de datos de aprendizaje o hacer ingeniería inversa en el código del modelo. Además, los hackers pueden forzar modelos de aprendizaje automático con la ayuda de un diseño especial de "inteligencia artificial opositora", para generar automáticamente muchas muestras atacantes y lanzarlas contra la solución protectora o el modelo de aprendizaje automático extraído hasta descubrir un punto débil del modelo. El impacto de estos ataques en sistemas antimalware que utilizan la IA podría ser devastador: un troyano mal identificado significa millones de dispositivos infectados y pérdidas de millones de dólares.
Por este motivo, se deben aplicar algunas consideraciones clave al usar la IA en sistemas de seguridad:
- El proveedor de seguridad debe comprender y abordar con cuidado los requisitos esenciales de rendimiento de los elementos de IA en el mundo real potencialmente hostil, requisitos entre los que se encuentran contar una barrera sólida contra posibles adversarios. Las auditorías de seguridad específicas del aprendizaje automático y la IA y el “red teaming” deben ser un componente clave del desarrollo de sistemas de seguridad que usan aspectos de la IA.
- Cuando se evalúa la seguridad de una solución que usa elementos de la IA, se debe considerar el grado de dependencia que tiene la solución respecto de datos y arquitecturas de terceros, ya que muchos ataques se originan en datos proporcionados por terceros (hablamos sobre fuentes de inteligencia de amenazas, conjuntos de datos públicos, modelos de inteligencia artificial previamente capacitados y externalizados).
- Los métodos de aprendizaje automático e IA no se deben considerar una solución milagrosa. Deben formar parte del enfoque de seguridad multicapa en el que las tecnologías de protección complementarias y el conocimiento humano trabajan en conjunto para protegerse mutuamente.
Es importante reconocer que, si bien Kaspersky tiene una amplia experiencia en el uso eficiente de aspectos de la IA como el aprendizaje automático y su subconjunto de aprendizaje profundo en sus soluciones de ciberseguridad, estas tecnologías no son la verdadera inteligencia artificial ni la inteligencia artificial general (AGI). Todavía queda un largo camino por recorrer hasta que las máquinas puedan funcionar de forma independiente y realizar la mayoría de las tareas de forma totalmente autónoma. Hasta entonces, casi todos los aspectos de la IA en ciberseguridad requerirán la orientación y la experiencia de profesionales humanos para desarrollar y perfeccionar los sistemas, aumentando sus capacidades con el tiempo.
Para obtener una descripción más detallada de los ataques más populares en algoritmos de aprendizaje automático/IA y los métodos de protección contra estas amenazas, lee nuestro documento técnico "AI under Attack: How to Secure Artificial Intelligence in Security Systems".
Productos relacionados

 Whitepaper
Whitepaper
WhitepaperMachine Learning for Malware Detection
Whitepaper
WhitepaperMachine learning and Human Expertise
Whitepaper
WhitepaperAI under Attack: How to Secure Machine Learning in Security System